

La Data Science pour modéliser les systèmes complexes par Alain Chautard (ECL 1989)
Optimiser la prédiction, l'estimation et l'interprétation
Ingénieur en data science dans le groupe Thales, Alain Chautard (ECL 1989) participe depuis 15 ans au développement et la mise en œuvre des systèmes d’information, notamment dans le domaine de la Gestion de projet. Il est en particulier en charge d’études concernant l’utilisation des données capitalisées et leur modélisation à des fins de prédictions pour la conduite du changement et l’amélioration continue. Une expertise qu’il a acceptée de partager dans cet article qui présente les grandes lignes de son livre «La Data Science pour modéliser les systèmes complexes» publié aux éditions «Dunod».
La data science est devenue un outil de prévision et d’aide à la décision indispensable aux ingénieurs, aux chercheurs et aux responsables en charge de la gestion des projets et des processus. La data science est aujourd’hui particulièrement adaptée aux systèmes linéaires qui font l’objet de nombreuses applications en entreprise depuis une vingtaine d’années.
Hors, les problèmes linéaires ne représentent que 20 % des problèmes rencontrés. Il existe en effet une classe de phénomènes (80 %), mis en évidence par Paul Lévy puis Benoît Mandelbrot, qui ne se comportent pas comme des processus gaussiens ou linéaires.
Ce sont principalement les problèmes économiques, sociologiques ou d’entreprise (économétrie), ainsi que ceux rencontrés en sciences physiques (météorologie, astronomie, sciences de la Terre, environnement de nombre de systèmes temps réel : par exemple les problèmes de rétrodiffusion et de propagation d’ondes radar en environnement marin) qui font appel à des outils d’analyse comme l’analyse fractale et les processus statistiques à queue lourde (Lois de Lévy…), et auxquelles les techniques classiques de traitement linéaire ne s’appliquent qu’avec de forts biais et incertitudes.
Ainsi, appliquer la data science aux systèmes complexes exige de dépasser les méthodes linéaires de modélisation généralement appliquées. En effet, si ces méthodes fonctionnent dans la plupart des environnements, elles présentent d’importants biais dès lors que l’on a affaire à des systèmes complexes (météorologie, physique non linéaire, économétrie, finance, etc.).
L’estimation des paramètres de systèmes complexes à partir de méthodes linéaires conduit à une erreur liée aux queues lourdes des répartitions des données (La théorie des intervalles de confiance en environnement gaussien n’est plus applicable pour des lois pour lesquels la notion d’écart type n’est pas définie. Nous devons donc estimer le type de loi et appliquer des estimateurs adaptés (paramètre d’échelle)
Les fortes fluctuations des systèmes complexes limitent la portée de la prédiction du comportement de ces systèmes. En effet, composés de cycles aléatoirement répartis à toutes les échelles d’observation, ces systèmes sont difficilement prédictibles, sauf à l’échelle d’un cycle. Cela implique une analyse locale des signaux qui s’appuie sur une connaissance d’un modèle local du système.
Les méthode de data science sont souvent des méthodes d’apprentissage qui projettent le signal observé sur des familles de fonctions arbitraires parce que simples (splines, fonctions polynômes, …). les paramètres de ces courbes estimés par l’apprentissage n’ont pas de sens physique. La connaissance du système et sa modélisation permettent de définir des bases de projection pertinentes d’un point de vue physique. Les paramètres identifiés deviennent facilement vérifiables à partir d’ordres de grandeur issus de la modélisation de ces systèmes.
L’application de la data science à des systèmes complexes passe par l’étape intermédiaire de la modélisation physique. Nous décrivons une méthode d’approche des phénomènes complexes basée sur la méthode systémique. La construction d’un modèle physique définit des ordres de grandeur et peut par ailleurs alimenter un système d’apprentissage (base de projection) ou des simulateurs détaillés qui donneront la précision requise. Nous obtenons dès lors des modèles maîtrisables, exploitables et performants en termes de prédiction, d’estimation et d’interprétation.
Nous appliquons cette approche à trois cas concrets représentatifs (environnement physique, marchés financiers, gestion de projet).
▶▶ Modélisation d’environnements de systèmes : fusion de données multi-senseurs par exemple (systèmes de détection, astronomie : réseaux de capteurs, sciences de la Terre). L’environnement d’un système est ce qui est situé en dehors de la frontière de ce système, là où il plonge ses capteurs pour acquérir de l’information qu’il restitue en termes d’actions vers cet environnement. La modélisation physique de ces environnements permet d’alimenter des algorithmes d’apprentissage (adaptation en temps réel de la fusion de données à son environnement) ou des simulateurs détaillés (dimensionnement de systèmes en conception).
▶▶ Modélisation de séries temporelles : dans la finance, certains indicateurs (CAC 40) décrivent l’interaction entre les agents économiques et le monde de l’entreprise. L’analyse de la série temporelle nous ramène nécessairement aux comportements élémentaires des agents (modélisation de la masse des agents sous forme d’un champ aléatoire). Ce modèle s’appuie sur une analyse du signal par ondelettes afin d’établir à chaque instant les cycles locaux du signal. Cette analyse en ondelettes conduit à établir une répartition conjointe des amplitudes et périodes des cycles. Nous pouvons ainsi alimenter un contrôle des placements financiers en « surfant » sur les cycles du signal.
▶▶ Contrôle statistique de processus en entreprise (gestion de projets, marketing, veille technologique). Une entreprise est caractérisée par un produit ou service. Une organisation et des processus sont établis afin de concevoir, développer, produire et vendre un produit ou un service. Cela a un coût : le prix de revient (PR). Le prix de vente (PV) est lié à l’équilibre économique de la concurrence. Le bénéfice (B = PV − PR) est à optimiser, ce qui exige de réfléchir à la commande des processus afin de limiter les coûts de non-qualité (entropie de l’entreprise, désordre organisationnel, gaspillage [qu’il s’agisse d’activités, de ressources ou de matière]). Un contrôle statistique met en oeuvre la commande du processus et permet de garantir une efficacité du processus en minimisant les coûts de non-qualité générés par celui-ci.
Dans ces 3 cas d’applications, la modélisation conduit à une estimation de paramètres pertinents. Leur estimation en temps réel (apprentissage) conduit à un pilotage adaptatif et optimal de ces systèmes en vue de finalités opérationnelles. L’application opérationnelle de ces méthodes est une commande adaptative de ces systèmes. Nous pourrions la modéliser par le schéma suivant :
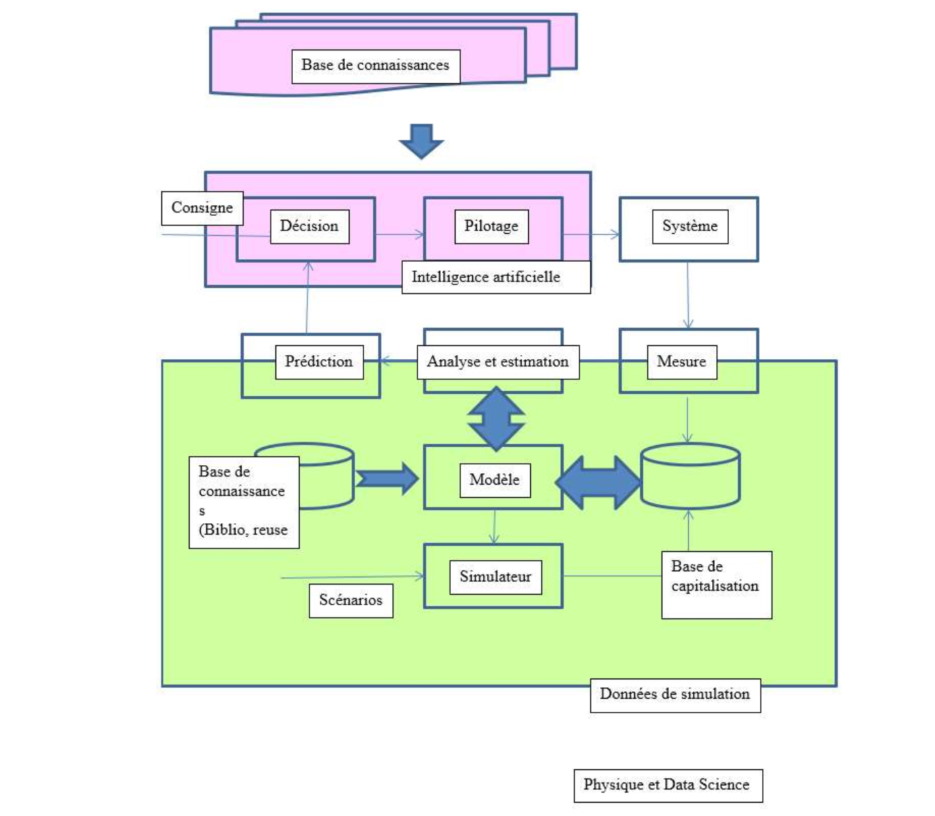
Nous ouvrons ainsi la data science à un élargissement de ses méthodes en termes de modélisation et d’outils : compléter les méthodes linéaires par les approches de la complexité (outils liés aux systèmes auto organisés, notamment) : bibliothèque d’algorithmes de haut niveau, data visualisation, architecture des simulateurs et traitements optimisés en temps de calcul et traitement de nombreuses données.
En conclusion, la complexité des systèmes temps réel et processus d’entreprise conduit à élargir les techniques traditionnelles d’analyse et de pilotage afin d’optimiser l’efficacité du système (estimation, prédiction interprétation) , cela par le biais de la commande adaptative. C’est un mode particulier de commande optimale. Il existe un parallèle entre système embarqué et système d’information, non seulement dans les principes de pilotage, mais aussi en ce qui concerne la datavisualisation, l’accès aux informations et leur mise en évidence pour une meilleure décision. La capitalisation des données utiles et un modèle de connaissance (modélisation des phénomènes, data science, intelligence artificielle) sont les axes à privilégier pour améliorer les performances du système, par exemple Knowledge Based Radar et pilotage de processus en entreprise (gouvernance adaptative).
Auteur

A lire
-
- La transformation mécatronique pour tous à horizon 2030 ?Numérique - La transformation mécatronique pour tous à... Contrairement à certaines prédictions qui annoncent un 21ème siècle exclusivement digital et...09 janvier 2020Lire la suite >
-
- Comment optimiser ses approvisionnements grâce à l’intelligence artificielle ?Numérique - Comment optimiser ses approvisionnements grâce à... Comment assurer la disponibilité de mes produits pour mes clients en utilisant un minimum de...09 novembre 2020Lire la suite >
-
- Les drones filaires d’Elistair à la conquête du marché américainNumérique - Les drones filaires d’Elistair à la conquête du... Située à Dardilly, la startup Elistair lancée en 2014 par deux Centraliens de Lyon, vient de...09 décembre 2020Lire la suite >
-
- Vers la 4ème dimension industrielle : de la Conception 4D de pièces imprimées en 4D par l'Industrie 4.0 - Patrick SerraferoNumérique - Vers la 4ème dimension industrielle : de la... Jamais la digitalisation des processus industriels n'aura été aussi rapide du fait d'une pandémie...04 février 2021Lire la suite >
-
- Cartographie des Arêtes de poisson de Lyon : des étudiants de l’ECL aux côtés du Service archéologique de la villeNumérique - Cartographie des Arêtes de poisson de Lyon : des... Ces dernières années, le développement des outils numériques a accéléré le rapprochement entre...06 septembre 2021Lire la suite >
-
- Smart city, smart territoire… au cœur des villes moyennesNumérique - Smart city, smart territoire… au cœur des villes... Les « smart cities » ou villes intelligentes représentent un enjeu majeur pour les grandes villes,...07 octobre 2021Lire la suite >
-
- Le système d’Informations, enjeu stratégique de la Smart CityNumérique - Le système d’Informations, enjeu stratégique de... Terme en vogue, la smart city, concept né aux États-Unis et désormais bien répandu, est au cœur des...06 janvier 2022Lire la suite >
-
- Rencontres ACL : menaces, solutions et enjeux de la cybersécuritéNumérique - Rencontres ACL : menaces, solutions et enjeux de... À l’heure où l’on compte 65 vols de données par seconde, où la cybercriminalité met en jeu chaque...08 janvier 2022Lire la suite >
-
- Eric Baudry (ECL 1983) raconte 40 ans d’évolution du numériqueNumérique - Eric Baudry (ECL 1983) raconte 40 ans... Depuis près de trois décennies, le numérique révolutionne notre quotidien, celui des entreprises,...03 octobre 2022Lire la suite >
-
- Antoine Chamieh (ECL 1992) - Les enjeux de l'identité numériqueNumérique - Antoine Chamieh (ECL 1992) - Les enjeux de... La confiance dans l'identité des individus, interagissant dans les espaces numériques en gestation,...03 octobre 2022Lire la suite >
-
- Fresque du Numérique : les clés pour comprendre et agir sur l’impact environnemental de nos pratiques numériquesNumérique - Fresque du Numérique : les clés pour comprendre... Atelier collaboratif et ludique, la Fresque du Numérique participe depuis fin 2019 à sensibiliser...28 mars 2023Lire la suite >
-
- Rencontre avec Florent Le Lain (ECL 2001) : Site Reliability Engineer Team Lead chez OVHcloudNumérique - Rencontre avec Florent Le Lain (ECL 2001) : Site... La tête dans le cloud et les pieds sur sa Terre bretonne, Florent Le Lain (ECL 2001) est aujourd’hui...28 juin 2023Lire la suite >
-
- Décarbonation et sobriété numérique : les engagements de Sylvain Baudoin (ECL 2000) au sein de BNP Paribas et du Shift ProjectNumérique - Décarbonation et sobriété numérique : les... Fin 2023, Sylvain Baudoin (ECL 2000) s’interrogeait sur LinkedIn sur la pertinence d’utiliser les...05 février 2024Lire la suite >
-
- Pollution numérique : vers une sobriété plus dynamique et moins dramatique par Sylvain Baudoin (ECL 2000)Numérique - Pollution numérique : vers une sobriété plus... Le numérique représentait en 2020 2,5 % de l’empreinte carbone française et 11 % de la consommation...26 février 2024Lire la suite >
-
- Sécurisation de l’Internet des Objets : rencontre avec Nicolas Courtin (ECL1991) Information Security Compliance Officer chez Kudelski IOTNumérique - Sécurisation de l’Internet des Objets :... Quels liens y-a-t-il entre les antiques décodeurs pirates Canal+, les ordinateurs quantiques et les...02 avril 2024Lire la suite >
-
- François Homps (17) : les supercalculateurs d’Eviden, de l’architecture au firmwareNumérique - François Homps (17) : les supercalculateurs... Des serveurs Edge aux supercalculateurs géants, François Homps (17) conçoit l’architecture...06 octobre 2025Lire la suite >
















Aucun commentaire
Vous devez être connecté pour laisser un commentaire. Connectez-vous.